
Activation Function

sigmoid

범위: [0,1]
문제점
- saturation되면 gradient 값이 사라짐(kill gradients)
- not zero centered: 모든 W가 같은 방향으로 움직임, 비효율적
- exp(): compute expensive
tanh

장점
- zero centered
단점
- still kills gradients when saturated
ReLU

장점
- Does not saturate (in +region)
- Very computationally efficient
- Converges much faster than sigmoid/tanh in practice (e.g. 6x)
- Actually more biologically plausible than sigmoid
단점
- Not zero-centered output
- saturated in -region (--> dead ReLU)
이를 해결하기 위해 positive bias 추가하기도
Leaky ReLU / PReLU

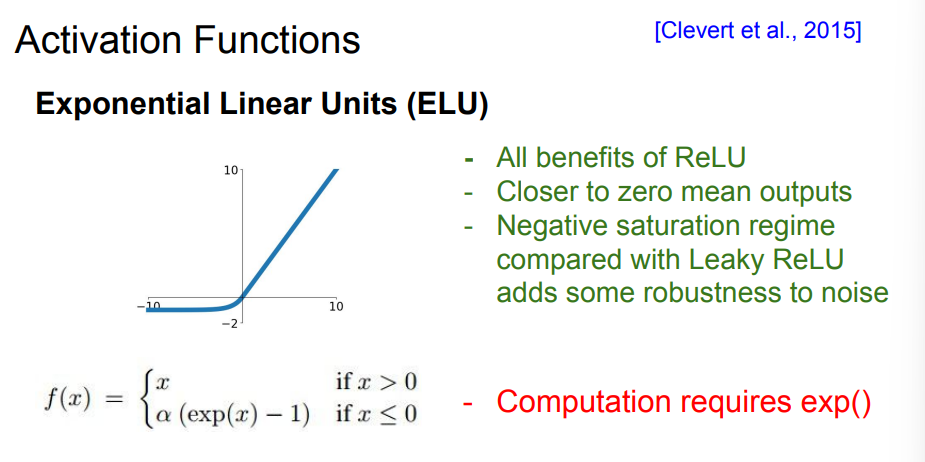
ELU
Maxout "Neuron"

단점
- parameter의 수가 두 배가 됨
Preprocess

이미지 데이터의 경우 zero-centering만 수행
train data에 대해 수행한 전처리는 test data에 대해서도 똑같이 사용해줘야 한다
Weight Initialization

가중치를 모두 0으로 초기화하게 되면 모든 뉴런이 같은 일을 하게 된다.(Symmetry Breaking)
Small random numbers

가중치의 편차를 0.01로 만듦
괜찮은 방법이지만 deeper networks에서는 출력값이 급격하게 줄어드는 문제가 발생한다.
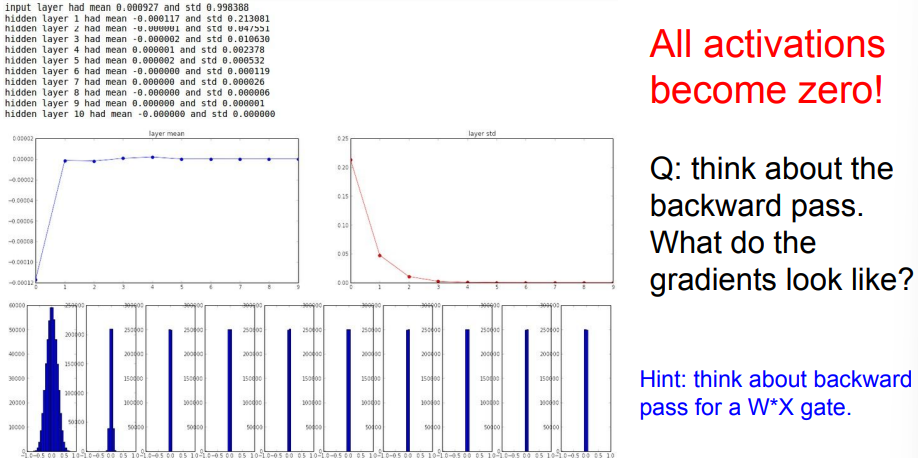
만약 가중치의 편차를 0.01이 아니라 1로 한다면?
saturation 발생, 값이 항상 -1이거나 1이 되는 현상이 발생하고 gradient는 모두 0값을 갖게 된다.

Xavier Initialization

입/출력의 분산을 맞춰주는 방법이 합리적임
하지만 ReLU에서는 좋지 못한 성능을 보인다
Batch Normalization

각 layer들의 입력이 unit gaussian을 만족시키도록 하려면 batch마다 평균과 분산을 계산해서 normalization을 수행해주면 된다.

보통 FC layer나 Convolution layers 뒤에 넣어준다
Conv layers는 특성상 activation map마다 평균과 분산을 계산해줘야 한다.
Hyperparmeter Optimization
cross-validation strategy

random search / grid search
