
우리 팀의 연구 주제는 멀티모달 모델인 CLIP 중에서도 FAS(Face anti-spoofing) 데이터셋에 대해 finetuning된 FLIP을 경량화하는 것을 목표로 한다.
FLIP 경량화를 위해 FAS Dataset이 필요한데, 우리는 FLIP 논문에 나온 데이터셋들 중에서도 MCIO 데이터셋을 먼저 활용하기로 하였다. MCIO는 MSU-MFSD(M), CASIA-MFSD(C), Replay-attack(I), OULU-NPU(O) 네 개의 데이터셋을 의미하며 추가적으로 CelebA-Spoof 데이터셋도 활용했다고 한다.
해당 데이터셋들의 정보와 전처리 방법은 FLIP 코드 중 dataset.md를 참고하면 된다.
하지만 생각보다 각각의 데이터셋을 얻는 것도 쉽지 않고, 이를 전처리하는 과정도 간단하지 않아 기록을 남긴다.
1. MSU-MFSD
첫번째 데이터셋은 dataset.md에 적힌 링크를 클릭해서 들어가면 404 에러가 발생한다.
따라서 바로 https://sites.google.com/site/huhanhomepage/datasetcode 이 링크로 접속하여 6번 데이터셋 우측에 있는 Download를 눌러준다.


그러면 위와 같이 데이터셋을 다운받을 수 있는 zip 파일들이 나온다.
이 파일들은 분할압축된 파일이니 각각을 압축해제하려고 하면 안된다.
우리 팀은 리눅스 서버를 사용하기 때문에 cat, unzip 명령어를 활용하였다.
2. CASIA-MFSD
dataset.md에서는 https://ieeexplore.ieee.org/document/6199754 여기를 가리키고 있는데, 대체 어떻게 다운받을 수 있는지 모르겠다. 공개적으로 다운받을 수 있는 링크는 없는 것 같다.
하지만 다행 구글링을 하던 중 다음과 같은 빛과 같은 코멘트를 발견했다.

http://www.cbsr.ia.ac.cn/english/FASDB_Agreement/Agreement.pdf
위 pdf에 동의서를 작성해서 해당 데이터셋의 권한을 갖고 있는 사람에게 전송하면 된다. Replay-attack(I), OULU-NPU(O) 도 유사한 방식으로 EULA(End User License Agreement)를 작성해야 데이터셋을 얻을 수 있는 것을 보아, 얼굴 사진처럼 개인정보에 민감한 데이터셋은 절차가 조금 까다로운 것 같다.
3. Replay-attack(I)
https://zenodo.org/records/4593128
위 링크에 들어가서 스크롤을 내리면 데이터셋을 요청할 수 있도록 코멘트를 전송하는 칸이 나온다.

Full name, Name of organization, Position/job title, Academic / professional email address / URL 등 많은 정보와 함께 작성을 해야한다.
다른 건 괜찮은데 MUST hold a permanent position 이라는 부분이 굉장히 난감했다. 영구적인 직책이 어떤걸 말하는 거며 일단 나는 일개 학생이기 때문에... 일단 최대한 정중하고 솔직하게 apply comment를 보냈다. 대신 지도교수님의 성함과 랩실 웹사이트 주소를 함께 기재했다.
그랬더니 아래처럼 EULA 양식을 보내주셨다! 그런데 이제 지도교수님께 부탁을 드려야 하는...
❗해당 사이트에 가입을 해야 apply를 보낼 수 있는데, 이 때 가입할 때에도 꼭 academic email을 사용해야 한다 ❗

4. OULU-NPU(O)
https://sites.google.com/site/oulunpudatabase/download

이 데이터셋도 마찬가지로 EULA 작성이 필요하다. 해당 링크에 들어가 Register 버튼을 눌러 구글폼을 작성하고 EULA 동의서를 작성해 jukka.komulainen@oulu.fi로 전송하면 된다. 그럼 다운받을 수 있는 링크와 비밀번호를 이메일로 전송해주신다. 비교적 간단한 과정에 신나서 땡큐메일을 또 보냈는데, You're welcome. Good luck with your research 이라고 답장해주셨다. 스윗한 Jukka...
5. CelebA-Spoof
https://drive.google.com/drive/folders/1OW_1bawO79pRqdVEVmBzp8HSxdSwln_Z
이 데이터셋은 친절하게 구글 드라이브 링크를 통해 다운받을 수 있다. 이 파일들도 분할 압축된 파일들이니 그에 맞춰 압축을 풀어주면 된다.
Data PreProcessing
데이터셋 다운만 받으면 끝나는 줄 알았지만 전처리 과정이 남아있다. 다운받은 데이터들은 대부분 .mp4, .avi 등 비디오 형식의 파일이기 때문에 필요한 부분만 png 파일로 바꿔주는 과정이 필요하다.
FLIP에서 알려주는 전처리 과정은 다음과 같다.
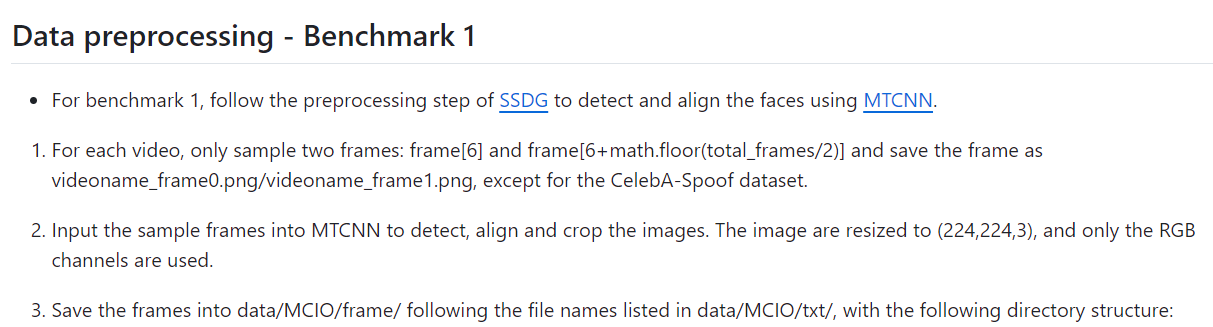

SSDG 논문에서 전처리한 방식을 그대로 따라하면 된다고 하는데, 이때 MTCNN이라는 툴이 필요하다.
그렇기 때문에 깃허브에 있는 MTCNN 코드를 먼저 가져온다.
git clone https://github.com/YYuanAnyVision/mxnet_mtcnn_face_detection.git

하지만 clone 해온 이 코드를 바로 사용할 수는 없다. 일단 우리가 가진 비디오에서 프레임을 추출해야 한다. 그리고 이 코드가 python2를 기준으로 작성되었기 때문에 약간의 수정도 필요하다.
1) pip install mxnet을 한 후 mxnet/numpy/utils.py에 들어가 아래와 같이 코드 수정
# mxnet/numpy/utils.py 파일
# bool = onp.bool 원래 코드
bool = onp.bool_ # 수정된 코드
2) mxnet_mtcnn_face_detection/mtcnn_detector.py 에서 아래 코드 삭제 혹은 주석 처리
from itertools import izipPython3에서 zip 함수가 내장 함수로 바뀌어 따로 import하지 않아도 되는 것 같다.
3) main.py 수정
import mxnet as mx
from mtcnn_detector import MtcnnDetector
import cv2
import os
import math
# MTCNN 설정
detector = MtcnnDetector(model_folder='model', ctx=mx.cpu(0), num_worker=4, accurate_landmark=False)
# 데이터 디렉토리 설정
data_root = 'path_to_MSU_MFSD' # 실제 데이터 경로로 변경
output_dir = 'data/MCIO/frame/msu'
# 비디오 파일 리스트
video_list = [f for f in os.listdir(data_root) if f.endswith('.mp4') or f.endswith('.mov')]
print(f"Found {len(video_list)} video files.")
# 프레임 추출 함수
def extract_frames(video_path):
cap = cv2.VideoCapture(video_path)
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
frame_indices = [6, 6 + math.floor(total_frames / 2)]
frames = []
for idx in frame_indices:
cap.set(cv2.CAP_PROP_POS_FRAMES, idx)
ret, frame = cap.read()
if ret:
frames.append((idx, frame))
else:
print(f"Failed to read frame {idx} from {video_path}")
cap.release()
return frames
# 얼굴 감지 및 정렬 함수
def process_frames(frames, output_path, video_name):
for idx, frame in frames:
results = detector.detect_face(frame)
if results is not None:
points = results[1]
chips = detector.extract_image_chips(frame, points, 224, 0.37)
for i, chip in enumerate(chips):
output_filename = f'{video_name}_frame{i}.png'
output_filepath = os.path.join(output_path, output_filename)
cv2.imwrite(output_filepath, chip)
print(f"Saved {output_filepath}")
else:
print(f"No face detected in frame {idx} of {video_name}")
# 데이터 처리
for video in video_list:
video_path = os.path.join(data_root, video)
frames = extract_frames(video_path)
# 비디오 이름에서 정보를 추출하여 적절한 출력 경로를 생성
video_name = os.path.splitext(video)[0]
if 'attack' in video_name:
output_path = os.path.join(output_dir, 'fake')
else:
output_path = os.path.join(output_dir, 'real')
os.makedirs(output_path, exist_ok=True)
print(f"Processing {video_name}...")
process_frames(frames, output_path, video_name)
print(f"Finished processing {video_name}.")전처리 과정에 안내되어 있던 대로 영상에서 frame[6]과 frame[6+math.floor(total_frames/2)]만 추출할 수 있도록 extract_frframes 함수를 추가하였으며, 비디오 이름에서 real/fake를 구분해서 폴더에 넣어줄 수 있도록 수정하였다.
위 코드를 실행하면 다음 사진과 같이 전처리가 잘 되어 들어간 것을 확인할 수 있다.

'ETC' 카테고리의 다른 글
| [캡스톤디자인프로젝트] T-FLIP: 어텐션 가중치 기반 지식 증류를 활용한 안면 위조 방지 모델 경량화 (2) | 2024.11.21 |
|---|---|
| [네이버 클라우드] 네이버 클라우드 파트타이머 근무 후기 (10) | 2022.10.15 |
| [Git / Github] VS Code에서 git clone으로 Github와 연결하기 (0) | 2021.10.13 |
| [IT 용어] - 컴파일과 빌드 (0) | 2021.08.08 |
| [IT 용어] - IT란? (0) | 2021.08.08 |