abstract
머신러닝 알고리즘들의 성능을 향상시킬 때, 모델들을 각각 훈련시킨 뒤 앙상블하는 기법을 많이 사용한다. 하지만 이렇게 앙상블된 모델로 prediction하는 과정은 굉장히 복잡하고 느리며(cumbersome), 많은 사람들이 사용하기에는 계산 비용이 크다는 단점이 있다.
이를 해결하기 위해, Caruana와 그의 collaborator들은 앙상블된 지식을 압축해서 하나의 모델에 넣는 것이 가능하다는 것을 보여주었는데, 본 논문에서는 이를 발전시킨 다른 지식 압축 기술을 제안한다. 앙상블된 모델들의 지식을 하나의 모델에 distilling함으로써 MNIST 데이터에 대해서 향상된 결과를 보여주며 acoustic model의 성능도 향상시켰다.
또한 새로운 유형의 앙상블 기법을 제안하여 기존에 비해 신속하게 병렬 훈련할 수 있도록 한다.
Introduction
우리는 보통 training stage와 deployment stage에서 비슷한 모델을 사용하지만 training stage와 deployment stage에서 각각 요구되는 바는 굉장히 다르다. 예를 들어 음성인식이나 객체인식의 경우 training을 할 때 굉장히 크고 중복되는 데이터셋에서 구조를 추출해야 하며, real time에서 수행될 필요가 없고 큰 계산 비용을 필요로 한다. 이와 달리, deployment 단계에서는 latency와 계산 비용에 대해 더 엄격한 요구 사항을 가지고 있다.
따라서 데이터에서 구조를 잘 추출할 수 있는 cumbersome model을 훈련시킨 뒤, 그 cumbersome model의 지식을 deployment에 적합한 small model로 전달하는 과정이 필요하며 그것을 "distillation"이라고 부른다. 이러한 연구는 2006년 Caruana와 그의 collaborator들에 의해 개척되었으며, large ensemble of models에서 얻은 지식을 작은 단일 모델에 전달할 수 있음을 확실하게 보여준다.
여기서 cumbersome model은 따로 훈련된 모델들의 앙상블이 될 수도 있고, 잘 정규화된 큰 단일 모델일 수도 있다.
우리는 보통 훈련된 모델에 있는 지식을 파라미터 값에서 확인하려는 경향이 있는데, 이 경우에 모델 형태를 어떻게 바꿔야 할지, 혹은 지식을 어떻게 유지시킬 수 있는지 등을 알아내기가 어렵다. 더 추상적인 관점으로 바라보는 것이 필요한데, 그것은 바로 input vectors에서 output vectors로의 학습된 매핑이 될 수 있다.
많은 클래스들을 구별하는 cumbersome model의 경우, 보통 정답에 대한 평균 로그 확률을 최대화하도록 학습한다. 이 때 정답뿐만 아니라 오답에도 똑같이 확률이 부여되며, 그 확률 값이 아무리 작더라도 다른 오답들에 비해 비교적 클 수 있다. 예를들어 BMW가 트럭으로 인식될 확률은 작지만 BMW가 당근으로 인식될 확률보다는 높을 것이다. 이러한 오답의 상대적인 확률값들은 모델이 데이터를 어떻게 이해하고 일반화하는지에 대한 정보를 제공한다. (위에서 말한 것처럼 모델의 지식을 추상적인 관점에서 바라본 것)
이렇게 잘 학습된 그리고 잘 일반화된 cumbersome model이 있다면, cumbersome model의 지식을 작은 모델에게 distilling할 때 그 모델과 같은 방식으로 일반화시키는 훈련이 가능하다. 이렇게 일반화된 작은 모델은 테스트 데이터에 대해서도 잘 동작하며, 일반적인 방식으로 훈련된 작은 모델보다 훨씬 더 좋다.
cumbersome model의 일반화 능력을 잘 전달할 수 있는 확실한 방법은 cumbersome model에 의해 생성된 class probabilites를 작은 모델을 훈련시키기 위한 "soft targets"으로 사용하는 것이다. 만약 cumbersome model이 간단한 모델들을 앙상블한 것이라면, 각각의 예측 분포의 산술 평균 혹은 기하 평균을 soft target으로 사용할 수 있다.
만약 soft target이 높은 entropy를 갖고 있다면, hard target보다 더 많은 정보를 제공하며 훈련 데이터들 간에 그래디언트 변동이 더 적다. 그로 인해, 원래 cumbersome model보다 더 적은 데이터와 더 높은 학습률로 학습이 가능하다.
(엔트로피가 높다는 것은 확률이 한 정답 클래스에 집중되지 않고 여러 클래스에 분포하는 경우를 뜻한다.)
(변동성이 적다는 것은 훈련 과정에서 모델이 업데이트되는 방향과 크기가 비교적 안정적이라는 것을 의미한다. 즉, 각 훈련 케이스에 대해 계산된 그라디언트가 크게 변동하지 않는다는 것이다. 이러한 상황에서는 학습률을 높여도 모델이 과하게 조정되거나 학습 과정이 불안정해질 확률이 낮다.)
아까 언급한 오답의 상대적인 확률값들에 더 이야기해보자. MNIST와 같은 태스크의 경우 cumbersome model이 거의 높은 확률로 정답을 맞출 수 있는데 이 때 학습된 함수에 있는 대다수의 정보는 soft target에 있는 매우 작은 확률값들의 비율이다. 예를 들어 '2'의 한 버전, 즉 한 이미지에 대해서 '3'으로 예측될 확률이 10^-6이고 '7'으로 예측될 확률이 10^-9라고 하자. 하지만 '2'를 가리키는 다른 버전의 이미지에서는 그 확률이 반대일 수도 있다. 즉 어떤 이미지에서는 '2'가 '3'처럼 보일 수도 있고, 또 다른 어떤 이미지에서는 '7'과 더 비슷하게 생겼을 수도 있다. 이러한 정보들이 데이터에 있는 풍부한 유사성 구조를 정의한다. 그런데 이런 작은 확률값들은 거의 0에 가까워서 cross entropy값에는 영향을 주지 못한다는 문제가 있다.
Carauna와 그의 collaborator들은 이러한 문제를 피하기 위해 class probabilities 대신 final softmax의 입력값으로 들어가는 logits을 사용했다. 그리고 cumbersome model과 small model에서 나온 두 logits의 제곱차를 최소화하는 방식으로 학습했다. 본 논문에서는 "distillation"이라고 부르는 더 일반적인 해결책을 제안하는데, 이는 cumbersome model이 적합한 soft target을 생산할 때까지 final softmax의 temperature를 증가시키는 것이다. 그리고 soft target을 이용해 small model을 학습시킬 때도 동일한 hight temperature을 사용한다. 나중에 언급하겠지만, cumbersome model의 logits을 매칭하는 것은 distillation의 특별한 경우이다. 무슨말일까..
small model을 학습시킬 때 사용하는 transfer set은 전부 unlabeled data일 수도 있고 기존 훈련 데이터일 수도 있다. 하지만 일반적으로 기존의 훈련 데이터셋을 이용했을 때 더 성능이 좋았으며, 특히 목적 함수에 작은 항을 추가했을 때 더 정답을 잘 예측하고 cumbersome model의 soft target과 잘 매칭되었다. 일반적으로 작은 모델이 soft target과 정확하게 일치되기는 어렵지만, 올바른 방향으로 가면서 오류를 범하는 과정은 도움이 될 수 있다.
(예를 들어 한 이미지를 '고양이'로 예측해야 하는 경우에 '고양이' 클래스에 대한 확률이 soft target처럼 높지 않을 수 있다. 하지만 고양이가 아닌 전혀 관련없는 클래스로 분류하는 것보다 '고양이'로 분류하는 쪽으로 오류를 범하는 것이 더 나으며 일반화 능력을 향상시킨다.)
Distillation
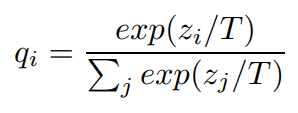
z_i = logit
z_j = other logits
q_i = probability
T = temperature
softmax는 특정 클래스의 logit(z_i)을 다른 클래스들의 logit들(z_j)과 비교해서 확률값(q_i)을 구한다. temperature T는 보통 1로 설정하며, 높은 값을 사용할수록 클래스들이 더 부드러운, 더 평평한 확률분포를 갖게된다.
간단한 형태에서의 distillation에서는, transfer set을 distilled model(small model)에 학습시켜 지식을 전달하는데, 이 때 high temperature의 softmax를 갖고있는 cumbersome model이 transfer set에 대해 생성한 soft target distibution을 이용한다. distilled model의 훈련과정에서는 cumbersome model과 마찬가지로 high T를 사용하며, 훈련이 종료된 후에는 T값으로 1을 사용한다.
(softmax에서 high T를 사용하면 모델이 부드러운 타겟 분포를 생성하는데, 이는 모델이 단순히 가장 가능성이 높은 클래스를 예측하는 것보다 더 세밀한 정보, 즉 다른 클래스들 간의 상대적 유사성을 학습하도록 돕는다. distilled model의 훈련이 완료된 후, 예측을 위해 모델을 사용할 때는 T를 다시 1로 설정한다. 이렇게 하면 모델의 출력이 실제 확률 분포에 더 가까워지며, 일반적인 분류 작업에 더 적합해진다.)
이러한 방법은 transfer set의 correct label을 사용해 성능을 더 향상시킬 수 있다. correct labels을 이용해 (아마도 cumbersome model의) soft targets값을 수정하는 방법도 있지만, 더 좋은 방법은 두 개의 다른 objective function의 가중 평균을 사용하는 것이다.
첫 번째 objective function은 cross entropy with soft targets을 계산한다.
distilled model, cumbersome model 모두 high T를 사용한 softmax의 결과값을 가지고 cross-entropy를 계산한다.
두 번째 objective function은 cross entropy with correct labels이다.
correct labels, 즉 hard target은 0과 1로 이루어져 있는 벡터이며, distilled model에서는 첫 번째 objective function에서와 똑같은 logits값을 사용하지만, softmax를 계산할 때 T에 1을 넣는다.
일반적으로 두번째 objective function에 낮은 가주치를 주었을 때 결과가 좋으며, soft target에 의해 생성된 gradient의 크기는 1/T^2로 스케일링되므로 soft/hard targets 모두 T^2을 곱해주는 것이 중요하다. 이렇게 해야 T값이 바뀌어도 soft/hard targets간의 상대적 기여도가 변하지 않는다.

Matching logits is a special case of distillation
아래 그림은 cross-entropy C를 z_i에 대해 미분한 식이다.
z_i = logit of the distilled model
z_j = other logits of the distilled model
v_i = logit of the cumbersome model
v_j = other logits of the cumbersome model
dC/dz_i = cross-entropy gradient
p_i = soft target probabilities
q_i = predicted probabilities by distilled model
N = number of classes
(softmax와 cross-entropy 미분 과정 - https://velog.io/@hjk1996/Cross-Entropy%EC%99%80-Softmax%EC%9D%98-%EB%AF%B8%EB%B6%84)



해당 과정에 대한 추가 설명 보충 필요
따라서 high T에서 logits이 zero-mean되어 있다고 가정한 경우, distillation은 1/2(zi − vi)^2 을 최소화하는 과정과 동등해진다. low T를 사용하는 것보다 high T를 사용할 때, 평균보다 훨씬 더 음수의 값을 갖는 logit들을 matching하는 데 더 많은 주의를 기울인다. 이런 음수의 값을 갖는 logit들은 cumbersome model에서 훈련되는 과정에서 비용 함수의 제약을 거의 받지 않기 때문에 잡음이 많을 수는 있다. 하지만 cumbersome model의 지식에 대한 유용한 정보를 전달한다. 따라서 이러한 두 특성을 고려해서 T값을 설정해야 한다. distilled model이 cumbersome model의 지식을 포착하기에 너무 작은 경우에는, 중간 정도의 T값이 잘 작동한다.
Preliminary experiments on MNIST
'Deep Learning' 카테고리의 다른 글
| [CS231n] Lecture 3: Loss Functions and Optimization (1) | 2023.12.10 |
|---|---|
| [CS231n] Lecture 2: Image Classification (2) | 2023.12.02 |
| [CS231n] Lecture 1: Introduction to Convolutional Neural Networks for Visual Recognition (0) | 2023.12.02 |
| 모두를 위한 딥러닝 시즌 2 [Pytorch] - Tensor Manipulation (0) | 2023.04.16 |



