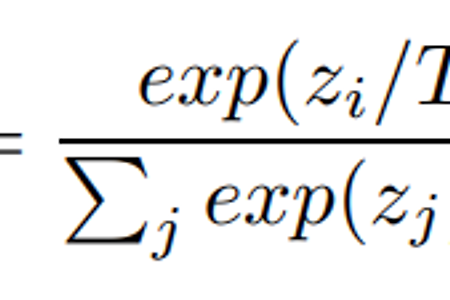-
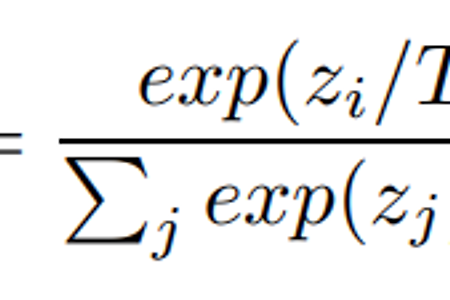 Deep Learning [Paper Review] Distilling the Knowledge in a Neural Network (작성중) abstract 머신러닝 알고리즘들의 성능을 향상시킬 때, 모델들을 각각 훈련시킨 뒤 앙상블하는 기법을 많이 사용한다. 하지만 이렇게 앙상블된 모델로 prediction하는 과정은 굉장히 복잡하고 느리며(cumbersome), 많은 사람들이 사용하기에는 계산 비용이 크다는 단점이 있다. 이를 해결하기 위해, Caruana와 그의 collaborator들은 앙상블된 지식을 압축해서 하나의 모델에 넣는 것이 가능하다는 것을 보여주었는데, 본 논문에서는 이를 발전시킨 다른 지식 압축 기술을 제안한다. 앙상블된 모델들의 지식을 하나의 모델에 distilling함으로써 MNIST 데이터에 대해서 향상된 결과를 보여주며 acoustic model의 성능도 향상시켰다. 또한 새로운 유형의 앙상블 기법을 제안하여 기존..
Deep Learning [Paper Review] Distilling the Knowledge in a Neural Network (작성중) abstract 머신러닝 알고리즘들의 성능을 향상시킬 때, 모델들을 각각 훈련시킨 뒤 앙상블하는 기법을 많이 사용한다. 하지만 이렇게 앙상블된 모델로 prediction하는 과정은 굉장히 복잡하고 느리며(cumbersome), 많은 사람들이 사용하기에는 계산 비용이 크다는 단점이 있다. 이를 해결하기 위해, Caruana와 그의 collaborator들은 앙상블된 지식을 압축해서 하나의 모델에 넣는 것이 가능하다는 것을 보여주었는데, 본 논문에서는 이를 발전시킨 다른 지식 압축 기술을 제안한다. 앙상블된 모델들의 지식을 하나의 모델에 distilling함으로써 MNIST 데이터에 대해서 향상된 결과를 보여주며 acoustic model의 성능도 향상시켰다. 또한 새로운 유형의 앙상블 기법을 제안하여 기존.. -
 카테고리 없음 [LeetCode] 344. Reverse String Link: https://leetcode.com/problems/reverse-string Reverse String - LeetCode Can you solve this real interview question? Reverse String - Write a function that reverses a string. The input string is given as an array of characters s. You must do this by modifying the input array in-place [https://en.wikipedia.org/wiki/In-place_algo leetcode.com Problem: Write a function that reverses a string. T..
카테고리 없음 [LeetCode] 344. Reverse String Link: https://leetcode.com/problems/reverse-string Reverse String - LeetCode Can you solve this real interview question? Reverse String - Write a function that reverses a string. The input string is given as an array of characters s. You must do this by modifying the input array in-place [https://en.wikipedia.org/wiki/In-place_algo leetcode.com Problem: Write a function that reverses a string. T.. -
 Algorithm [LeetCode] 125. Valid Palindrome Link: https://leetcode.com/problems/valid-palindrome Valid Palindrome - LeetCode Can you solve this real interview question? Valid Palindrome - A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric cha leetcode.com Problem: A phrase is a palindrome if, after con..
Algorithm [LeetCode] 125. Valid Palindrome Link: https://leetcode.com/problems/valid-palindrome Valid Palindrome - LeetCode Can you solve this real interview question? Valid Palindrome - A phrase is a palindrome if, after converting all uppercase letters into lowercase letters and removing all non-alphanumeric characters, it reads the same forward and backward. Alphanumeric cha leetcode.com Problem: A phrase is a palindrome if, after con.. -
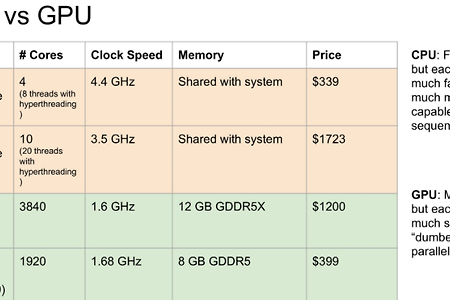 카테고리 없음 [CS231n] Lecture 8: Deep Learning Software CPU vs GPU CPU는 높은 clock 속도를 가지지만 GPU는 CPU와 비교할 수 없는 Core 수를 가지고 있다 이러한 GPU를 다루기 쉽도록 최적화된 라이브러리는 아래와 같다 파란색은 CPU, 빨간색은 GPU, 노란색은 최적화한 GPU CPU와 그냥 GPU를 비교하면 거의 60~70배 정도 차이가 난다 Deep Learning Frameworks 일반적인 유명한 Deep Learning Frameworks로는 Caffe, PyTorch, TensorFlow가 있다. 현업에서는는 TensorFlow을 많이 사용하며 연구에서는 PyTorch를 사용하는 추세이다. PyTorch PyTorch에는 3가지 추상화(Abstraction)가 있다 Tensor : ndarray로, gpu에서 돌아간다 Var..
카테고리 없음 [CS231n] Lecture 8: Deep Learning Software CPU vs GPU CPU는 높은 clock 속도를 가지지만 GPU는 CPU와 비교할 수 없는 Core 수를 가지고 있다 이러한 GPU를 다루기 쉽도록 최적화된 라이브러리는 아래와 같다 파란색은 CPU, 빨간색은 GPU, 노란색은 최적화한 GPU CPU와 그냥 GPU를 비교하면 거의 60~70배 정도 차이가 난다 Deep Learning Frameworks 일반적인 유명한 Deep Learning Frameworks로는 Caffe, PyTorch, TensorFlow가 있다. 현업에서는는 TensorFlow을 많이 사용하며 연구에서는 PyTorch를 사용하는 추세이다. PyTorch PyTorch에는 3가지 추상화(Abstraction)가 있다 Tensor : ndarray로, gpu에서 돌아간다 Var.. -
 카테고리 없음 [CS231n] Lecture 7: Training Neural Networks II Optimization Problem of SGD 수평 방향보다 수직 방향의 가중치 변화에 더 민감하다 때문에 지그재그 모양으로 그리면 학습함 이는 바람직하지 않으며 고차원 공간에서 더 심각하게 나타난다 local minimum이나 saddle point에서 학습이 멈출 수 있다. valley가 있는 손실 함수에서 locally flat한 곳을 만나면 gradient 값이 0이 되어 학습이 멈출 수 있다. saddle point에서도 local minimum은 아니지만 gradient가 0이 된다. saddle point 근처에서도 굉장히 작은 gradient 값을 갖게 되어 update가 느려지는 단점이 있다. 고차원, very large network에서는 local minimum이 굉장히 드물지만 ..
카테고리 없음 [CS231n] Lecture 7: Training Neural Networks II Optimization Problem of SGD 수평 방향보다 수직 방향의 가중치 변화에 더 민감하다 때문에 지그재그 모양으로 그리면 학습함 이는 바람직하지 않으며 고차원 공간에서 더 심각하게 나타난다 local minimum이나 saddle point에서 학습이 멈출 수 있다. valley가 있는 손실 함수에서 locally flat한 곳을 만나면 gradient 값이 0이 되어 학습이 멈출 수 있다. saddle point에서도 local minimum은 아니지만 gradient가 0이 된다. saddle point 근처에서도 굉장히 작은 gradient 값을 갖게 되어 update가 느려지는 단점이 있다. 고차원, very large network에서는 local minimum이 굉장히 드물지만 .. -
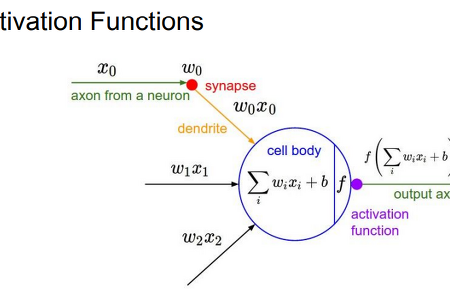 카테고리 없음 [CS231n] Lecture 6: Training Neural Networks,Part I Activation Function sigmoid 범위: [0,1] 문제점 - saturation되면 gradient 값이 사라짐(kill gradients) - not zero centered: 모든 W가 같은 방향으로 움직임, 비효율적 - exp(): compute expensive tanh 장점 - zero centered 단점 - still kills gradients when saturated ReLU 장점 - Does not saturate (in +region) - Very computationally efficient - Converges much faster than sigmoid/tanh in practice (e.g. 6x) - Actually more biologically plau..
카테고리 없음 [CS231n] Lecture 6: Training Neural Networks,Part I Activation Function sigmoid 범위: [0,1] 문제점 - saturation되면 gradient 값이 사라짐(kill gradients) - not zero centered: 모든 W가 같은 방향으로 움직임, 비효율적 - exp(): compute expensive tanh 장점 - zero centered 단점 - still kills gradients when saturated ReLU 장점 - Does not saturate (in +region) - Very computationally efficient - Converges much faster than sigmoid/tanh in practice (e.g. 6x) - Actually more biologically plau.. -
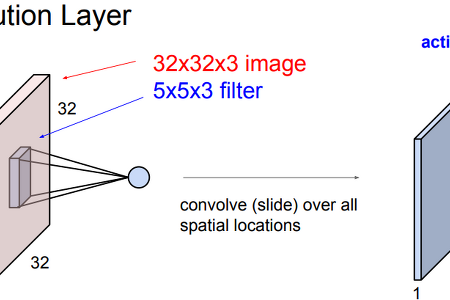 카테고리 없음 [cs231n] Lecture 5: Convolutional Neural Networks Convolution Layer convolution은 좌상단에서 시작해서 하나의 결과값을 output activation map에 저장한다. activation map의 크기는 slide를 어떻게 하느냐에 따라 달라진다. 한 layer에서 여러 개의 filter를 사용해 다양한 특징을 추출할 수 있다. 각 필터마다 각각의 map을 생성하며 필터들이 계층적으로 학습된다. Stride stride는 filter를 몇 칸씩 움직이는지를 결정하는 숫자이다. stride가 2라면 두 칸씩 sliding하며 convolution을 수행한다. 7*7 이미지를 3*3 filter로 연산을 수행할 때 stride을 3으로 한다면 이미지에 fit되지 않는다. 불균형한 결과를 만들어내므로 수행되지 않는다. 이런 경우 pa..
카테고리 없음 [cs231n] Lecture 5: Convolutional Neural Networks Convolution Layer convolution은 좌상단에서 시작해서 하나의 결과값을 output activation map에 저장한다. activation map의 크기는 slide를 어떻게 하느냐에 따라 달라진다. 한 layer에서 여러 개의 filter를 사용해 다양한 특징을 추출할 수 있다. 각 필터마다 각각의 map을 생성하며 필터들이 계층적으로 학습된다. Stride stride는 filter를 몇 칸씩 움직이는지를 결정하는 숫자이다. stride가 2라면 두 칸씩 sliding하며 convolution을 수행한다. 7*7 이미지를 3*3 filter로 연산을 수행할 때 stride을 3으로 한다면 이미지에 fit되지 않는다. 불균형한 결과를 만들어내므로 수행되지 않는다. 이런 경우 pa.. -
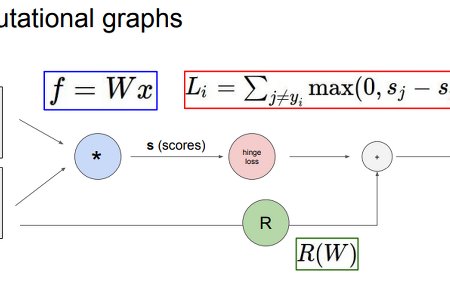 카테고리 없음 [CS231n] Lecture 4: Introduction to Neural Networks computational graph는 머신 러닝에서 일반적으로 사용되는 방법으로, 복잡한 함수를 그래프 형태로 표현하는 데 사용된다. Computational graph를 사용하면 어떤 함수든지 그래프 형태로 표현할 수 있으며, 이 그래프의 각 노드는 연산 단계를 나타낸다. 제시된 예제에서는 입력 변수로 x와 W를 가지는 선형 분류기를 설명한다. 곱셈 노드는 행렬 곱셈을 나타내며, 파라미터 W와 데이터 x의 곱셈은 점수 벡터(score vector)를 출력한다. Computational graph를 사용하면 backpropagation이라는 기술을 사용할 수 있다. Backpropagation은 gradient를 얻기 위해 computational graph 내의 모든 변수에 대해 chain rule을 ..
카테고리 없음 [CS231n] Lecture 4: Introduction to Neural Networks computational graph는 머신 러닝에서 일반적으로 사용되는 방법으로, 복잡한 함수를 그래프 형태로 표현하는 데 사용된다. Computational graph를 사용하면 어떤 함수든지 그래프 형태로 표현할 수 있으며, 이 그래프의 각 노드는 연산 단계를 나타낸다. 제시된 예제에서는 입력 변수로 x와 W를 가지는 선형 분류기를 설명한다. 곱셈 노드는 행렬 곱셈을 나타내며, 파라미터 W와 데이터 x의 곱셈은 점수 벡터(score vector)를 출력한다. Computational graph를 사용하면 backpropagation이라는 기술을 사용할 수 있다. Backpropagation은 gradient를 얻기 위해 computational graph 내의 모든 변수에 대해 chain rule을 .. -
 Deep Learning [CS231n] Lecture 3: Loss Functions and Optimization Loss Functions 예측 함수 f(x,W) = Wx 왼쪽 숫자들은 임의의 행렬 W를 가지고 예측한 클래스 스코어이다. 고양이 샘플 데이터에서 cat score는 3.2로 car score 5.1보다 낮고, 개구리 샘플 데이터에서 frog score는 -3.1로 cat과 car에 대한 score보다 낮은 값을 갖고 있다. 우리는 정답 클래스가 해당 데이터에서 가장 높은 점수가 되는 분류기를 원하기 때문에 해당 분류기가 성능이 별로 좋지 않다는 것을 알 수 있다. 하지만 스코어를 눈으로 보며 분류기의 성능을 평가하는 것은 좋은 방법이 아니다. 문제를 해결할 알고리즘을 만들고, 어떤 W가 가장 좋은지 결정하기 위해서는 W가 좋은지 나쁜지를 정량화 할 방법이 필요하다! 손실함수는 W를 입력받아 각 스코어..
Deep Learning [CS231n] Lecture 3: Loss Functions and Optimization Loss Functions 예측 함수 f(x,W) = Wx 왼쪽 숫자들은 임의의 행렬 W를 가지고 예측한 클래스 스코어이다. 고양이 샘플 데이터에서 cat score는 3.2로 car score 5.1보다 낮고, 개구리 샘플 데이터에서 frog score는 -3.1로 cat과 car에 대한 score보다 낮은 값을 갖고 있다. 우리는 정답 클래스가 해당 데이터에서 가장 높은 점수가 되는 분류기를 원하기 때문에 해당 분류기가 성능이 별로 좋지 않다는 것을 알 수 있다. 하지만 스코어를 눈으로 보며 분류기의 성능을 평가하는 것은 좋은 방법이 아니다. 문제를 해결할 알고리즘을 만들고, 어떤 W가 가장 좋은지 결정하기 위해서는 W가 좋은지 나쁜지를 정량화 할 방법이 필요하다! 손실함수는 W를 입력받아 각 스코어..